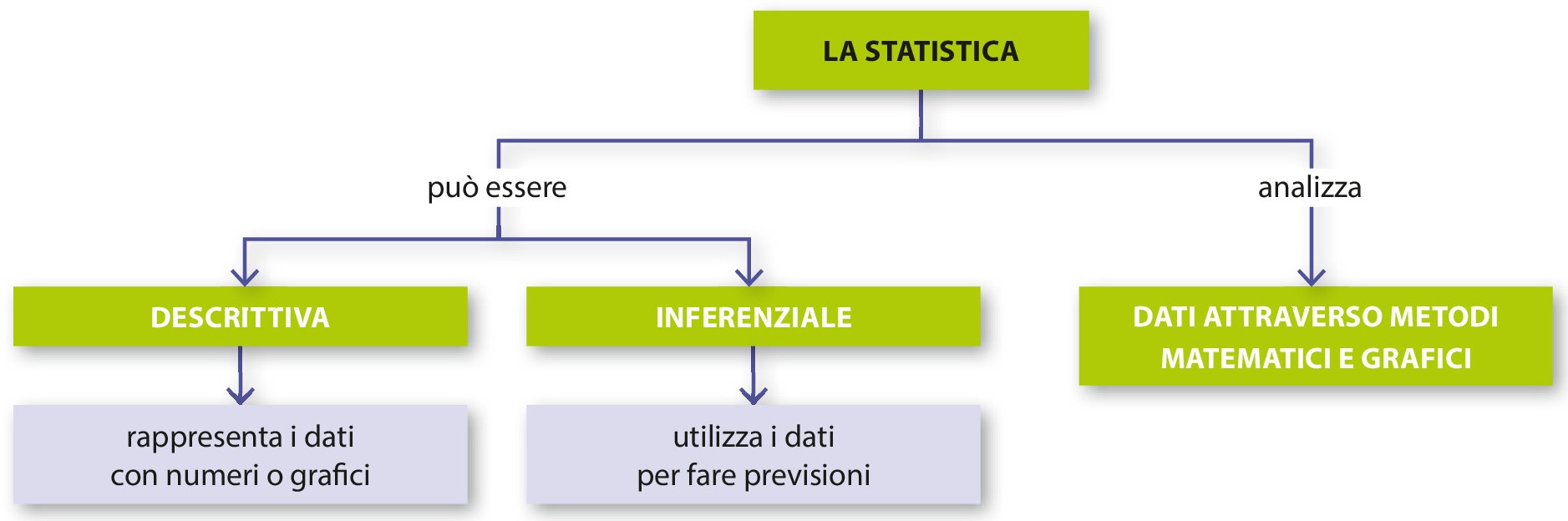
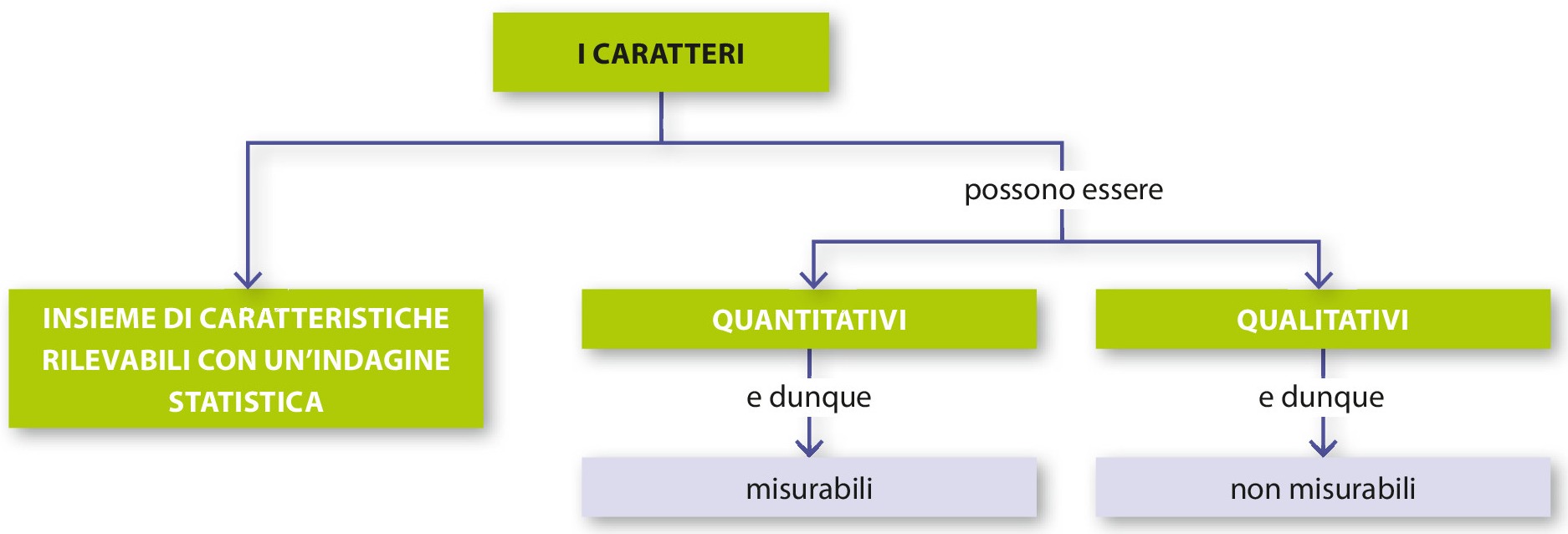
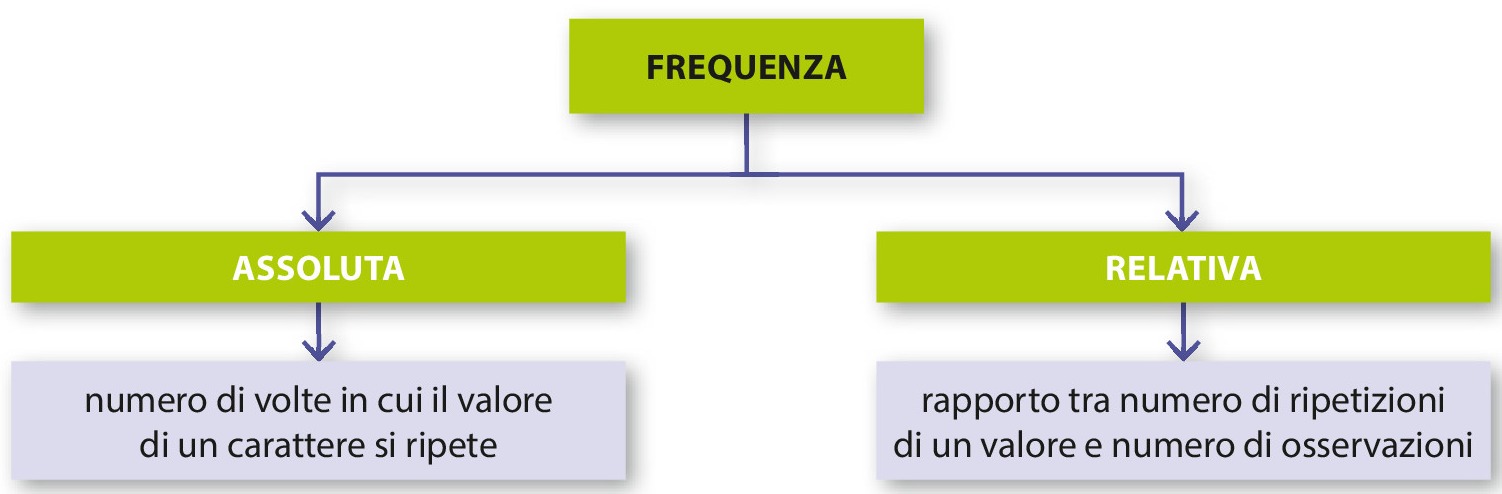
Confrontare le distribuzioni
Proviamo a fare un passo avanti: immaginiamo che Francesca, la nostra insegnante di matematica, voglia confrontare i risultati della sua classe in matematica con quelli ottenuti sempre dalla sua classe ma in scienze. Questa volta il confronto è un po’ più complesso. Gli studenti sono sempre gli stessi ma le materie sono diverse e naturalmente cambiano anche le prove sottoposte dalle insegnanti. Tuttavia, quello che Francesca potrebbe chiedersi è questo: “Esiste un rapporto fra le capacità dei miei allievi in matematica e quelle in scienze? I risultati delle due prove variano insieme o, invece, non esiste nessuna relazione? E se facessi lo stesso confronto con le prove di italiano la relazione sarebbe la stessa o cambierebbe? Gli studenti bravi in matematica vanno bene anche in scienze o in italiano?”.
Per trovare risposta a questi interrogativi dobbiamo confrontare le distribuzioni dei voti delle due materie (matematica e scienze) all’interno dello stesso campione (la stessa classe). Potremmo affidarci a una semplice osservazione grossolana per capire l’andamento generale e valutare cioè se a buoni voti in una materia corrispondono buoni voti nell’altra. Tuttavia, questo non ci consente di stimare in modo accurato e preciso se esista effettivamente una relazione; in particolare, nel caso di un campione molto ampio, sarebbe quantomeno difficile fare una stima accurata. Si tratta di trovare un modo scientificamente affidabile per capire se le due variabili (i voti di matematica e i voti di scienze) seguono una distribuzione talmente simile da risultare in qualche misura collegate tra loro. Esistono alcune procedure statistiche che vengono definite bivariate, perché consentono di analizzare l’andamento di due variabili differenti in una stessa popolazione, come nel nostro esempio.
Una delle possibili procedure è calcolare la covarianza, che si esprime con la seguente formula:
COV(x,y) = (x1 - mx )(y1 - my ) + (x2 - mx)(y2 - my) + ... + (xn - mx)(yn - my)/n
Dove x1, x2, …, xn sono i valori che compongono la prima serie di dati (i voti in matematica), mx è la loro media; y1, y2, …, yn sono i valori che compongono la seconda serie di dati (i voti in scienze), my è la loro media, e n è il numero totale degli elementi del campione (gli studenti della classe).
La covarianza può essere positiva (superiore a 0), negativa (inferiore a 0) o nulla (uguale a 0).
Da un punto di vista qualitativo una covarianza positiva può indicare che le due serie di dati seguono un andamento simile: nel nostro esempio, questo significa che gli studenti che vanno bene in matematica tendono ad avere buoni voti anche in scienze. In altri termini, una covarianza positiva indica che le due serie di dati hanno un comportamento concorde. Viceversa, una covarianza negativa indica che i dati hanno comportamenti discordi: nel nostro caso, gli studenti con voti più alti in matematica hanno voti bassi in scienze. In questo caso si parla di correlazione inversa o anticorrelazione. Se invece la covarianza risulta uguale a zero, questo indica che i dati non sono in relazione diretta tra loro, ovvero il rendimento in matematica e quello in scienze sono sostanzialmente indipendenti.
Per valutare la covarianza da un punto di vista quantitativo è utile introdurre un’altra grandezza: l’indice di correlazione di Pearson r.
Facciamo prima un passo indietro. Il valore della covarianza dipende dal range di riferimento, dal campione da cui è stato calcolato, dall’unità di misura. Potremmo, per esempio, ottenere come covarianza 127. Ma cosa significa 127? Indica che la covarianza c’è, non ha valore 0, ma quanto è forte? Quanto significativo è il legame tra la variabile x e la variabile y? L’indice di correlazione serve a rispondere proprio a questa domanda: calcolare il valore di r è utile in quanto esso indica con precisione il livello di relazione tra due fenomeni.
Per calcolarlo è necessario applicare la seguente formula:
r= COV(x,y)/√VAR(x)VAR(y)
Dove COV (x, y) indica la covarianza tra la variabile x e la variabile y, VAR (x) sta per la varianza della variabile x, VAR (y) sta per la varianza della variabile y.
L’indice di correlazione r può assumere valori compresi tra -1 e 1. Se la correlazione è uguale a 0, significa che le due variabili non sono collegate tra di loro e il loro andamento sarà indipendente. Più il valore di r si avvicina a 1, più il legame sarà forte e le variabili saranno fortemente associate: per esempio, se la covarianza di 127 ha come codice di correlazione 0,8, questo vuol dire che il legame tra le due serie di dati è significativo; se invece il valore è di 0,2, cioè più vicino a 0, questo indica che il legame non è così forte.
Diversamente, valori negativi di r indicano l’esistenza di una correlazione inversa, che tanto è più forte più ci si avvicina a -1.
Possiamo rappresentare graficamente la correlazione avvalendoci di un piano cartesiano in cui su un asse riportiamo i valori di una variabile e sull’altro quelli dell’altra variabile, per esempio i voti di scienze sull’asse orizzontale e i voti di matematica su quello verticale. Questo tipo di diagramma, detto diagramma di dispersione, consente di rappresentare il tipo di relazione intercorrente tra le due variabili.
Le figure A, B e C mostrano tre possibili casi. Riprendiamo il nostro esempio: i colleghi di Francesca si sono incuriositi alla sua ricerca e decidono di calcolare l’indice di correlazione anche all’interno delle loro classi. Nelle tre immagini, corrispondenti a tre classi, ogni quadratino blu indica i voti di uno studente in matematica e scienze.
Nella figura A i dati tendono a disporsi intorno a una retta che parte dall’origine (in basso a sinistra) e punta in alto a destra. La pendenza della retta è positiva: nella prima classe i voti alti in matematica si accompagnano a voti alti in scienze e l’indice di correlazione è positivo.
Nella figura B i dati sono ancora disposti intorno a una retta ma con pendenza opposta. Nella seconda classe voti alti in matematica corrispondono a voti bassi in scienze e viceversa, l’indice di correlazione è negativo.
Nella figura C, che rappresenta la terza classe, i dati sono sparsi: in questo caso non c’è correlazione tra i voti di matematica e i voti di scienze e l’indice di correlazione è molto vicino a 0.
Infine, è importante evidenziare come l’indice r di correlazione non sintetizzi un rapporto causa-effetto, ma si limiti a “fotografare” un andamento comune delle due distribuzioni: non sarà l’aumento del rendimento in scienze a provocare un aumento dei voti di matematica in caso di correlazione positiva, o viceversa. O meglio, non possiamo escludere questa ipotesi, ma nemmeno confermarla. Per sbilanciarsi in quel senso occorreranno ulteriori analisi statistiche più avanzate.