2 LA CODIFICA DEI COLORI E DELLE IMMAGINI
2 LA CODIFICA DEI COLORI E DELLE IMMAGINI
La codifica dei colori avviene quando gli 0 e gli 1 vengono usati per rappresentare i colori.
Come fanno degli 0 e 1 a diventare dei colori?
Per rispondere dobbiamo prima capire che cosa sia un colore e poiché i colori si vedono solo quando c’è luce, la prima domanda a cui dobbiamo rispondere è: che cos’è la luce?
Parliamo un po’ di ottica…
La luce proviene principalmente dal Sole, una stella che emette luce bianca. La luce del Sole arriva sulla Terra attraversando l’atmosfera; una parte della luce solare raggiunge il suolo, colpisce i materiali e li colora.
Se l’oggetto illuminato è nero, significa che la sua superficie ha assorbito tutta la luce bianca che lo ha colpito. Se l’oggetto appare bianco, significa che la sua superficie ha diffuso (cioè riflesso in tutte le direzioni) tutta la luce del Sole. Se l’oggetto viene percepito verde, significa che la sua superficie ha assorbito tutta la luce bianca, tranne il verde che invece viene diffuso e può essere percepito dall’occhio.
La luce bianca è formata da un insieme di radiazioni elettromagnetiche (colori), diverse fra loro, che possono essere viste separatemente dall’occhio umano quando, per esempio, la luce attraversa un prisma e viene scomposta nei colori dell’arcobaleno.
Ogni colore corrisponde a una frequenza dello spettro visibile, che è l’insieme di tutti i possibili colori.
Per esempio le onde elettromagnetiche con una frequenza compresa fra 405 e 480 THz (o con una lunghezza d’onda compresa fra 740 e 625 nm) corrispondono alla radiazione elettromagnetica che l’occhio umano percepisce come rosso.
I modelli di colore
I colori che vediamo sugli schermi dei computer o degli smartphone non sono tutti i colori dello spettro visibile, ma solo una parte.
Lo spettro del visibile può, infatti, essere suddiviso in numerosi sottoinsiemi, che prendono il nome di spazio dei colori. Tra i più utilizzati ci sono lo spazio colore RGB e lo spazio colore CMYK.
Una volta stabilito lo spazio dei colori che si intende utilizzare, è necessario un modo per rappresentare in forma numerica ogni singolo colore contenuto in quello spazio. I modelli di colore fanno proprio questo, definiscono i colori indicando, per ciascuno, come è stato ottenuto.
Il modello RGB
Il modello RGB è un modello additivo che ottiene i colori dello spazio RGB sommando al nero il contributo di tre luci, una ▶ rossa, una ▶ verde e una ▶ blu che prendono il nome di componenti del colore.
Se proiettiamo su una superficie bianca, nel buio (nero) più totale, una luce rossa, una verde e una blu, otteniamo l’effetto illustrato in figura: la sovrapposizione totale (bianco) o parziale (ciano, magenta, giallo) delle tre luci di partenza.
Regolando la luminosità delle tre componenti è possibile ottenere tutti i colori dello spazio RGB. Il modello RGB usa un byte per codificare ogni componente di colore. Questo significa che ciascuna componente (considerata in base 10) può assumere un valore compreso fra 0 e 255.
I principali programmi applicativi consentono di regolare i tre valori numerici e di ottenere il colore desiderato.
esempio

Talvolta i valori numerici delle componenti del colore vengono espresse in base esadecimale.
Il modello CMYK
I modelli additivi, come il modello RGB, funzionano molto bene quando il colore, dal punto di vista fisico, viene ottenuto come una luce (composta da tre luci colorate). La radiazione risultante raggiunge direttamente l’occhio e viene interpretata come colore. Per questo motivo i modelli additivi sono adatti per la rappresentazione dei colori sui monitor.
Quando però i colori devono essere stampati su carta, il discorso cambia totalmente perché il colore finale percepito dall’occhio non proviene direttamente da una sorgente di luce, ma lo raggiunge indirettamente, arrivando sotto forma di luce riflessa.
Per spiegare questa nuova condizione occorre quindi un altro modello che tenga conto del fatto che il colore proviene dalla luce diffusa dal supporto su cui avviene la stampa (carta).
Il modello CMYK è un modello sottrattivo, che ottiene i colori sottraendo al bianco il contributo di quattro inchiostri, uno ▶ ciano, uno ▶ magenta, uno ▶ giallo e uno ▶ nero, che anche in questo caso prendono il nome di componenti del colore.
Tralasciamo, per il momento, il nero.
Se, cercando di riprodurre l’effetto delle tre luci sul muro, versiamo su un foglio bianco, nella luce bianca più totale, un inchiostro ciano, uno magenta e uno giallo, otteniamo l’effetto illustrato in figura: al centro, dove i tre inchiostri si sovrappongono, risulta un colore quasi nero; intorno si vedono altri tre colori (il rosso, il verde e il blu), ottenuti dalla sovrapposizione parziale delle tre componenti di partenza.
I modelli sottrattivi partono da una condizione di presenza di luce bianca, proveniente da una sorgente di luce (per esempio il Sole). Il foglio di carta bianco riflette totalmente la luce bianca. Gli inchiostri colorati versati sul foglio sottraggono lunghezze d’onda al bianco riflesso, facendo percepire all’occhio il colore finale desiderato.
esempio
Per vedere il ciano, si deve stampare il ciano perché toglie dal bianco riflesso dal foglio tutti i colori tranne il ciano, che infatti viene diffuso e percepito dall’occhio.
Per vedere il rosso, occorre stampare giallo + magenta perché la loro sovrapposizione toglie dal bianco riflesso dal foglio tutti i colori, tranne il rosso.
Regolando la quantità delle tre componenti (ciano, magenta, giallo) è possibile ottenere tutti i colori dello spazio CMYK.
Come il modello RGB anche il modello CMYK utilizza un byte per codificare ogni componente di colore, ma invece dei numeri compresi fra 0 e 255, usa le percentuali. Maggiore è la percentuale di un determinato inchiostro, maggiore è la quantità di inchiostro che viene stampato.
|
Colore |
% C |
% M |
% Y |
% K |
|
ciano |
100 |
0 |
0 |
0 |
|
magenta |
0 |
100 |
0 |
0 |
|
giallo |
0 |
0 |
100 |
0 |
|
bianco |
0 |
0 |
0 |
0 |
|
rosso |
0 |
100 |
100 |
0 |
|
verde |
100 |
0 |
100 |
0 |
|
blu |
100 |
100 |
0 |
0 |
Lo sapevi che
La luce che proviene dal Sole raggiunge l’occhio direttamente, ma la luce che proviene dalla Luna è una radiazione indiretta: si tratta sempre della luce del Sole che viene riflessa sulla superficie del nostro satellite naturale.
prova tu
Vero o falso?
- Il modello RGB è di tipo additivo.
- V F
- Le componenti RGB vengono espresse esclusivamente in base esadecimale.
- V F
- Nel modello CMYK il magenta viene ricavato dal rosso, dal nero e dal blu.
- V F
Dalla visualizzazione in RGB alla stampa in CMYK
Ogni volta che scattiamo una fotografia l’immagine acquisita viene visualizzata sullo schermo con i colori RGB.
Il modello RGB, con i suoi 3 byte (8 bit per ciascuna componente, in totale 24 bit) è in grado di rappresentare 224 = 16 777 216 colori che sono più che sufficienti quando la foto vene visualizzata unicamente sui monitor, come accade per esempio alle immagini che compaiono sui siti web.
Se, invece, l’immagine deve essere stampata, occorre necessariamente convertire i colori RGB nei corrispondenti colori del modello CMYK per poter tradurre le variazioni di luminosità dei pixel in quantità di inchiostro versato sul foglio.
Nonostante il modello CMYK disponga di 4 byte per rappresentare i colori (in totale 32 bit), i colori CMYK risultano mediamente più sbiaditi rispetto a quelli RGB. Questo dipende dal fatto che i due spazi colore non si sovrappongono perfettamente e quindi i colori più vivaci, presenti nello spazio RGB, non si possono riprodurre nel modello CMYK.
Finora abbiamo tralasciato il nero che corrisponde alla K del modello CMYK.
Verosimilmente la K si riferisce alla parola ▶ key perché il nero è un elemento di riferimento fondamentale nella colorazione delle immagini. Secondo alcuni, invece, la K si riferisce all’ultima lettera di ▶ black, usata per non creare confusione, dato che B, viene usata nel modello RGB per indicare il blu. Quindi ricorderebbe che la stampa è in quadricromia, cioè usa 4 inchiostri (CMYK).
La cartuccia nera viene usata perché mescolando ciano, magenta e giallo (100%, 100%, 100%, 0%), non si ottiene un nero pieno, ma un colore quasi nero (più simile a un marrone molto scuro) che prende il nome di bistro, nella pratica poco usato.
Il colore che siamo abituati a vedere nei testi stampati è quello della cartuccia nera (0%, 0%, 0%, 100%) che viene chiamato nero piatto.
Il nero ricco, utilizzato invece nelle immagini, viene ottenuto aggiungendo al nero anche altre componenti di colore che permettono di ottenere il nero caldo, quello freddo e una vasta gamma di neri in base all’effetto finale che si desidera ottenere.
La codifica delle immagini
La codifica delle immagini avviene quando gli 0 e gli 1 vengono usati per rappresentare i disegni e le fotografie.
Quando con la fotocamera dello smartphone scatti un selfie, la tua immagine nel mondo reale viene trasferita sul display e diventa un’immagine digitale; esistono alcune app che consentono di trasformare il tuo naso in quello di un cane generando artificialmente un’altra immagine digitale che viene sovrapposta alla precedente.
Sia che si tratti di una fotografia scattata per mezzo di un sensore, sia che si tratti di un disegno nato direttamente all’interno di un calcolatore, l’immagine digitale deve essere trasformata in una sequenza di bit. Solo così, infatti, può essere memorizzata, eventualmente elaborata oppure trasmessa e, naturalmente, visualizzata sul display.
Esistono due tecniche principali per trasformare un’immagine digitale in una sequenza di 0 e 1:
- codifica raster (chiamata anche ▶ bitmap): proprio attraverso la quale le immagini vengono suddivise in quadratini che prendono il nome di pixel (▶ picture element) e a ciascuno di essi viene associata un’informazione numerica sul colore;
- codifica vettoriale: con la quale le immagini vengono rappresentate mediante delle primitive geometriche, che successivamente vengono trasformate in pixel per poter essere visualizzate sullo schermo.
Lo sapevi che
Nel 1987 John Knoll scattò una fotografia della moglie Jennifer seduta sulla spiaggia di Bora Bora e, in seguito, la usò per presentare Photoshop, il software per modificare le immagini, che aveva sviluppato insieme al fratello. Trattandosi di un’immagine particolarmente adatta a essere ritoccata, in seguito anche i tecnici della Adobe e della Apple la utilizzarono per presentare i propri software.
La codifica raster
La codifica raster sovrappone all’immagine originale (una fotografia o un disegno digitale) una griglia che consente di individuare i pixel, cioè le unità elementari, in cui viene suddivisa l’immagine digitale.
Successivamente a ciascun pixel viene associato un colore che solitamente è quello predominante nel quadratino. L’informazione sul colore associato a ciascun pixel viene quindi salvata come successione di 0 e 1 all’interno di un file.
esempio
Abbiamo un’immagine in bianco e nero che rappresenta un triangolo.
La codifica raster sovrappone una griglia al triangolo, stabilisce se all’interno di ciascun pixel c’è più bianco o più nero, associa a ciascun pixel solo 1 bit e utilizzando la convenzione 0 = bianco e 1 = nero codifica la predominanza di bianco oppure di nero in ogni pixel.
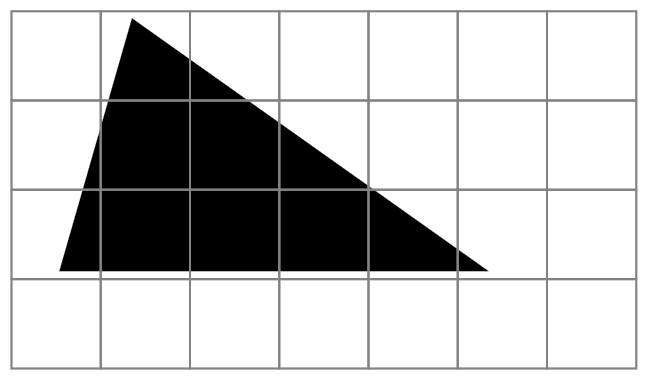
In questo modo l’immagine può essere salvata come mappa di bit (bitmap) e il file che contiene le informazioni sull’immagine digitale avrà al suo interno la seguente sequenza:
0100000
0110000
0111100
0000000
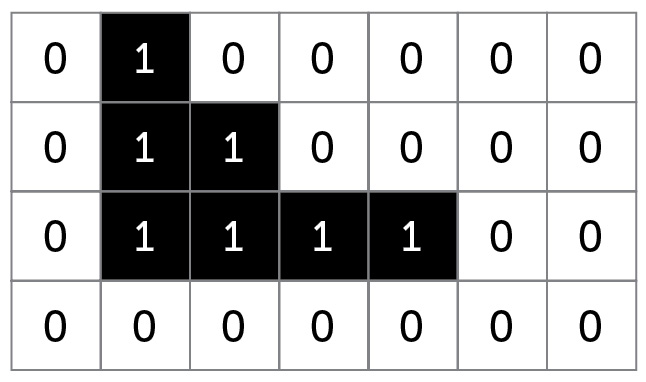
Il formato del file che contiene la sequenza dei bit ottenuti, nei casi come quello del precedente esempio, prende il nome di bitmap e ha estensione .bmp (▶ unità 5).
prova tu
Completa le seguenti frasi.
- La codifica che suddivide l’immagine in pixel si chiama
- Il formato di file che salva le immagini come mappe di bit si chiama
La tavolozza e la profondità
I primi monitor dei computer avevano una grafica monocromatica, cioè utilizzavano un solo colore, talvolta il bianco su sfondo nero, ma più spesso il verde su sfondo nero. Per codificare questa presenza (o assenza) di colore utilizzavano 1 bit per pixel (1 bpp), infatti con 1 bit è possibile codificare 21 = 2 colori (il colore del testo e quello dello sfondo).
1981 – Grafica CGA (Color Graphics Adapter)
Consentiva di utilizzare 16 colori in modalità testuale, codificati nel modello RGB, di cui solo 4 colori visualizzabili contemporaneamente in modalità grafica.
La codifica dei colori CGA utilizzava 4 bit per pixel (4 bpp), infatti con 4 bit è possibile codificare 24 = 16 colori. Trattandosi di pochi bpp, i colori utilizzabili venivano inseriti all’interno di una tabella (chiamata tavolozza o palette) e i bit associati al pixel rappresentavano un indice numerico (binario) attraverso il quale era possibile individuare una specifica riga della tabella e, di conseguenza, uno dei colori disponibili. Per esempio il colore nero aveva indice zero (0000).
I 16 colori della tavolozza CGA erano predefiniti dalla scheda grafica e non modificabili.
Per la modalità grafica era però possibile scegliere quale sottoinsieme di 4 colori utilizzare. La scheda grafica metteva a disposizione alcune sotto-palette, anch’esse predefinite, che contenevano quaterne di colori differenti selezionabili singolarmente.
|
N. |
Tavolozza CGA (alta intensità) |
|
|
0 |
|
default |
|
1 |
|
11 - ciano chiaro |
|
2 |
|
13 - magenta chiaro |
|
3 |
|
15 - bianco |
Lo sapevi che
Intorno al 1870 in Francia si sviluppò il puntinismo, un movimento pittorico che otteneva le immagini accostando i colori, ma mantenendoli separati fra loro. Il principio utilizzato era lo stesso che oggi ci consente di percepire le immagini digitali visualizzate su un monitor.
I pixel dei display, infatti, sono elementi piccolissimi che l’occhio umano fonde tra loro, dando l’impressione di un’immagine uniforme.
Lo sapevi che
La scheda video CGA visualizzava correttamente i colori RGB sui monitor dei computer, ma a causa di un bug, sui televisori i colori si sovrapponevano rendendo i testi poco leggibili.
Gli sviluppatori di console per videogiochi sfruttarono il bug come vantaggio: i colori sovrapposti, infatti, ne formavano altri, aumentando le possibilità grafiche della scheda video.
1984 – Grafica EGA (Enhanced Graphics Adapter)
Consentiva di utilizzare tutti i 16 colori CGA in modalità grafica, permettendo di selezionarli da un totale di 64 colori. A ogni pixel venivano associati 6 bit (6 bpp) attraverso i quali era possibile codificare 26 = 64 tinte differenti.
Come per la grafica CGA, i colori all’interno della tavolozza EGA venivano individuati da un indice numerico binario.
1987 – Grafica VGA (Video Graphics Array)
Consentiva di visualizzare fino a 256 colori, tutti in modalità grafica, associando a ogni pixel un byte (8 bpp) con il quale venivano codificati 28 = 256 colori all’interno di una tavolozza.
I 256 colori della tavolozza VGA predefinita potevano essere modificati attraverso i software scegliendo tra 218 = 262 144 colori RGB.
Come per le grafiche precedenti, i colori all’interno della tavolozza VGA venivano individuati da un indice numerico binario.
Lo sapevi che
Lo standard VGA si è diffuso così tanto da essere ancora presente nei PC. Le attuali schede grafiche sono in grado di gestire lo standard VGA prima ancora di caricare i loro specifici driver. Inoltre, ancora oggi, anche se sempre più raramente, per collegare le schede grafiche ai monitor e/o ai videoproiettori, vengono utilizzati cavi, chiamati VGA.
La profondità
Il numero di bit usati per codificare il colore di ogni singolo pixel (bpp) prende il nome di ▶ profondità del colore dell’immagine.
La profondità del colore delle immagini digitali è aumentata nel tempo. Con il numero maggiore di bpp usati, è cresciuta anche la disponibilità di tinte e l’uso delle tavolozze è diventato via via sempre più scomodo.
Per profondità di colore elevate invece di utilizzare un indice numerico per individuare le tinte nella tavolozza, si è preferito codificare i colori direttamente nelle tre componenti cromatiche del modello RGB utilizzando un byte per ciascuna di esse.
La grafica Truecolor, attualmente utilizzata nei calcolatori, associa a ogni pixel 3 byte (24 bpp), uno per codificare la luminosità del rosso, uno per il verde e uno per il blu. Le tinte disponibili sono quelle dell’intero spazio colore RGB, cioè circa 16 milioni di colori per ciascun pixel. Si stima che i colori che l’occhio umano è effettivamente in grado di distinguere siano 10 milioni, quindi molti di meno di quelli visualizzabili con 24 bit.
Attualmente esiste anche la grafica con colore a 32 bit (4 byte) che, diversamente da come suggerirebbe il nome, non rende disponibili 232 colori distinti (che non sarebbero distinguibili dall’occhio umano), ma codifica le tinte del Truecolor con 3 byte e utilizza, opzionalmente, il quarto byte per codificare il canale alfa che serve per descrivere la trasparenza (o l’opacità) del pixel.
All’interno dei file raster, oltre al colore dei pixel, sono contenute altre importanti informazioni che riguardano l’immagine digitale. Per esempio:
- la risoluzione dell’immagine: cioè il numero di pixel che formano la griglia;
- la posizione assunta dai pixel all’interno della griglia di pixel.
Il numero totale di bit usati per codificare tutte le informazioni associate a ogni pixel prende il nome di profondità dell’immagine.
Conoscendo la risoluzione e la profondità dell’immagine è possibile calcolare lo spazio di memoria occupato dall’immagine digitale.
esempio
Un’immagine con le caratteristiche indicate a lato occupa:
640 × 480 × 8 bit = 307 200 byte = 300 kB
infatti 307 200 : 1024 = 300
A questo spazio va aggiunto quello necessario per memorizzare nel file altri dati come, per esempio, quelli della risoluzione dell’immagine.
Lo sapevi che
Per codificare le immagini in scala di grigi occorre associare a ciascun pixel più di un bit, come accade per le immagini colorate.
prova tu
Completa le seguenti frasi
- Il numero di bit che codifica il colore di ogni pixel si chiama
- Il numero di bit che codifica tutte le informazioni di ogni pixel si chiama
- Il numero di pixel che compongono la griglia dell’immagine viene detta
La risoluzione delle immagini e i dpi
Il pixel è l’unità elementare di un’immagine virtuale, indipendente dal dispositivo su cui verrà visualizzata (monitor) o stampata (carta).
Le dimensioni di un’immagine virtuale vengono espresse in pixel.
I display sono formati da pixel materiali chiamati ▶ punti, ciascuno dei quali suddiviso in subpixel rossi, verdi e blu, che permettono di visualizzare i colori RGB sullo schermo.
In generale non esiste nessun collegamento tra i pixel di un’immagine virtuale e i pixel materiali che compongono un monitor.
Se la risoluzione dell’immagine virtuale è:
- uguale alla risoluzione del monitor: a ogni pixel virtuale corrisponde un pixel materiale e, di conseguenza, in ciascun pixel materiale il colore viene visualizzato sulla base delle informazioni associate al pixel virtuale corrispondente;
- maggiore della risoluzione del monitor: parte dell’informazione originale non viene visualizzata, ma la riproduzione risulta di solito molto buona;
- minore della risoluzione dello schermo: è possibile o visualizzare un’immagine piccola sullo schermo, o ingrandirla assegnando a più pixel materiali l’informazione di un solo pixel virtuale, ottenendo un effetto quadrettato.
Se un monitor di grandi dimensioni ha una risoluzione uguale a quella dell’immagine virtuale, l’immagine materiale verrà visualizzata di grandi dimensioni, non quadrettata.
Se la dimensione in centrimetri (o ▶ pollici, inch) dello schermo viene fissata, aumentando il numero di pixel materiali (dot), la loro dimensione in centimetri (o inch) diminuisce e in 1 cm2 (o 1 inch2) di monitor rientra una quantità maggiore di dot.
Solitamente i pixel materiali dei monitor dei PC sono quadrati quindi è anche possibile dire, che diminuendo la dimensione dei dot sullo schermo, in 1 cm (o 1 inch) orizzontale o verticale, si trova un numero maggiore di punti.
Quando la densità dei pixel materiali aumenta, considerando 1 inch, i ▶ punti per pollice (dot per inch, dpi) aumentano e, in generale, la qualità dello schermo migliora perché il monitor diventa in grado di visualizzare anche le immagini con alta risoluzione.
Un monitor con tantissimi punti è di alta qualità, ma se i pixel sono grandi, avrà dimensioni enormi. Un monitor di piccole dimensioni può comunque avere tantissimi punti (piccoli), se i dpi sono tanti. Per esempio gli schermi degli smartphone con alta risoluzione hanno tanti pixel materiali ed elevati valori di dpi, perché i display hanno piccole dimensioni in centimetri.
Per ottenere una buona stampa bisogna partire da un’immagine virtuale ad alta risoluzione (il problema della quadrettatura riguarda anche la stampa su carta). In secondo luogo occorre stabilire le dimensioni in centimetri (o in pollici) dell’immagine che si vuole ottenere sulla carta.
Con queste due informazioni occorre quindi stabilire se la risoluzione dell’immagine di partenza consente di ottenere un’immagine su carta di almeno 300 dpi.
Per visualizzare un’immagine con le stesse dimensioni in centimetri su un monitor, invece, è sufficiente partire da un’immagine virtuale a risoluzione più bassa. Infatti, i monitor normalmente hanno un valore più basso di dpi perché i pixel materiali dei display sono più distanziati dei punti depositati sulla carta durante la stampa.
Le immagini virtuali utilizzate per il web, hanno tradizionalmente una risoluzione di 72 dpi, cioè una risoluzione inferiore a quella delle immagini usate nella stampa. Questa caratteristica introduce un ulteriore vantaggio: lo spazio occupato in memoria dall’immagine virtuale è inferiore e il tempo impiegato per caricarla sul web diminuisce drasticamente.
Lo sapevi che
Nel 1984 la Apple lanciò sul mercato il Macintosh, il primo computer a introdurre il paradigma WYSIWYG (▶ Un po’ di storia). Ai tempi le tipografie stampavano con un singolo punto grande 1/72 di pollice (punto tipografico). Il monitor del Macintosh fu costruito per contenere esattamente 72 pixel × 1 inch, questo gli consentiva di visualizzare i contenuti alla stessa dimensione, sia che si trovassero sullo schermo, sia che si trovassero stampati sul foglio.
ApprofondiMENTO
QUANTO VALE UN POLLICE?
Il pollice è un’unità di misura di lunghezza che non appartiene al Sistema Internazionale, ma che è ampiamente utilizzata nei paesi anglosassoni ed equivale a 2,54 cm. Le dimensioni dei monitor vengono solitamente espresse in lunghezza in pollici delle diagonali.
prova tu
Cerca nel web un’immagine di un panorama che abbia le caratteristiche per essere stampata non quadrettata su un foglio A4.
educazione civica
IL DIRITTO D’AUTORE
La distinzione tra alta e bassa risoluzione in Italia ha rilevanza giuridica perché la legge n. 2 del 9 gennaio 2008, integrando l’articolo 70 della legge n. 633 del 1941 sul diritto d’autore, ha previsto che i siti senza scopo di lucro possano pubblicare liberamente attraverso la rete Internet, a titolo gratuito, immagini e musiche a bassa risoluzione o degradate per uso didattico o scientifico.
SCHEDA CLIL
Steganography
Sometimes, you want to code and communicate pieces of information in a way that is not visible to others. Especially if you are a spy and you need to send reserved data. A way to do that is to use steganography. You can take a photo of your cat, for example. And alter the least significant bits of every pixel (or, of a pixel every twenty pixels, or something like that). Let’s say that your cat is digitalized with a color depth of 24 bits (RGB, 3 channels x 8 bits each).
Every picture element can turn in a hue among 16 millions possible colors. Human eye can’t see any difference if you change the least significant bit of a channel (Red, Green or Blue: Blue is often preferred, because it’s the worst recognizable by our eyes). Technically, you’ve got a different color.
Actually, no one can find evidence of it. So, if you code information into such bit, and you have many bits – on many different pixels – which you can alter, you are automatically able to hide external information (not related to your cat!) inside your cat picture. The more space you leave between altered pixels, the more difficult is to recognize that your image hides a secret!
La codifica vettoriale
La codifica vettoriale individua gli elementi geometrici (linee, cerchi ecc.) che sono presenti all’interno dell’immagine originale (che potrebbe essere una fotografia, ma più comunemente è un disegno o uno schema tecnico) e successivamente li codifica con un formato opportuno.
esempio
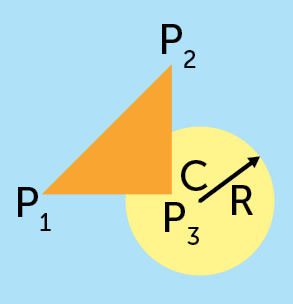
| Il disegno a lato può essere descritto vettorialmente come tre linee che uniscono tre punti più un cerchio di centro e raggio noti.
linea (P1, P2)
linea (P2, P3)
linea (P3, P1)
cerchio (C, R)
|
|
All’interno del file vettoriale vengono memorizzate delle primitive geometriche che, prima di poter essere rappresentate sullo schermo, devono essere convertite in pixel.
Conoscendo le due codifiche per le immagini, viene spontaneo porsi una domanda: è meglio l’informazione raster o quella vettoriale? Dipende: nella computer grafica vengono utilizzate entrambe:
- le immagini raster funzionano bene per rappresentazioni a toni continui, con mescolanze di colori morbide, occupano molto spazio in memoria e richiedono molto tempo per essere convertite in immagini vettoriali;
- le immagini vettoriali generano tratti di solito più netti e sono poco adatte all’editing delle fotografie, ma occupano poco spazio in memoria e possono essere facilmente convertite in immagini raster.
La maggiore differenza tra le due codifiche si nota quando le immagini vengono ridimensionate, cioè ridotte o ingrandite (scalamento). Ingrandendo un’immagine su uno schermo, infatti, il numero di pixel utilizzato deve aumentare e i pixel aggiunti possono contenere nuove informazioni oppure no.
Nel caso delle immagini raster l’informazione non aumenta con l’ingrandimento. I pixel aggiunti possono essere calcolati come media di colore fra due pixel vicini o come duplicazione di altri pixel ma l’informazione rimane invariata. Ingrandendo un’immagine raster oltre una certa soglia, quindi, sgrana e sembra quadrettata.
Le immagini vettoriali, invece, poiché tracciano una linea tra due punti, quando vengono ingrandite aggiungono informazione: i punti della linea disegnata aumentano all’aumentare della dimensione della linea e sono punti nuovi. Ingrandendo un’immagine vettoriale, non viene persa definizione.
ApprofondiMENTO
I VETTORI
In matematica esistono due tipi di grandezze: quelle scalari che sono descrivibili da un numero (detto intensità) e quelle vettoriali che per essere definite hanno bisogno, oltre che dell’intensità, anche di una direzione e un verso.
Le grandezze vettoriali vengono rappresentate usando delle frecce che prendono il nome di vettore.
La lunghezza della freccia rappresenta l’intensità, la direzione è rappresentata dalla retta sulla quale giace la freccia e il verso è rappresentato dalla punta della freccia. Il punto da cui parte la freccia si chiama origine del vettore. I vettori si usano per modificare le primitive geometriche.
ApprofondiMENTO
L’ANIMAZIONE VETTORIALE
Le immagini vettoriali generate al computer possono essere usate nella computer grafica, anche 3D, per realizzare gli effetti speciali dei film o i cartoni animati vettoriali.
Il primo lungometraggio di animazione fu Biancaneve e i sette nani di Walt Disney che venne proiettato per la prima volta nel 1937. All’epoca l’animazione scaturiva dalla magia del disegno a mano libera su moltissimi fogli in sequenza che, fatti scorrere velocemente, creavano l’illusione del movimento dei personaggi.
Solo 60 anni più tardi, nel 1995, la nuova casa cinematografica, Pixar (costituita da Steve Jobs, il fondatore della Apple), specializzata in animazione computerizzata, lanciò il primo lungometraggio realizzato interamente al computer, con grafica vettoriale 3D: Toy Story in collaborazione con Disney.
Negli anni seguenti uscirono A Bug’s Life megaminimondo, Alla ricerca di Nemo, Gli incredibili e moltissimi altri.
Oltre ad abbassare notevolmente i tempi di produzione, la grafica vettoriale digitale riduce i costi per realizzare le scenografie virtuali, per gestire le luci e per muovere le inquadrature. Per creare elaborazioni in grafica vettoriale 3D, infatti, si possono utilizzare vari software, fra cui AutoCAD, Autodesk Maya, 3D Studio Max, Rhinoceros e software liberi e gratuiti come, per esempio, Blender.
Clic!
Tecnologie informatiche per il primo biennio